

#075 - Whisper | Your Personal Transcription Service
Create a local meeting transcription system to create detailed meeting notes

Welcome folks. Today we are looking at a very handy transcription tool that I use in my workflow to capture action items and information from design meetings.

It's easy to attend a meeting, especially these days. But what about taking detailed notes that you will need to reference or rely upon in the future? In my experience, you have a few options:
Paid AI transcription services like fireflies, read.ai, otter.ai - these work well but it's yet another subscription service to manage and wrestle with. They don't make it easy to manage your own data and also require an external bot participant to join your meetings which results in clients wondering who is this and what's going on?
Listen and take notes manually, and as soon as you need to participate you can't take notes. I cannot meaningfully think, talk, listen and type at the same time.
Participate and hope somebody else takes notes with your best interests at heart.
Use the built-in MS Teams or Zoom recorders which have administrative/security barriers.
Build a custom tool. Something simple and secure. That's what I do.
This article breaks down the architecture and logic of a personal transcription tool that built to solve this problem for myself.
You are welcome to use it and adapt it to your own needs.
The Architecture of a Solution
From first principles, the problem is one of cognitive load. You cannot simultaneously be a high-value participant in a technical discussion and a high-fidelity scribe. The processes are mutually exclusive. Therefore, the logical solution is to decouple the act of capturing information from the act of synthesizing it.
Our tool achieves this with a simple, robust pipeline:
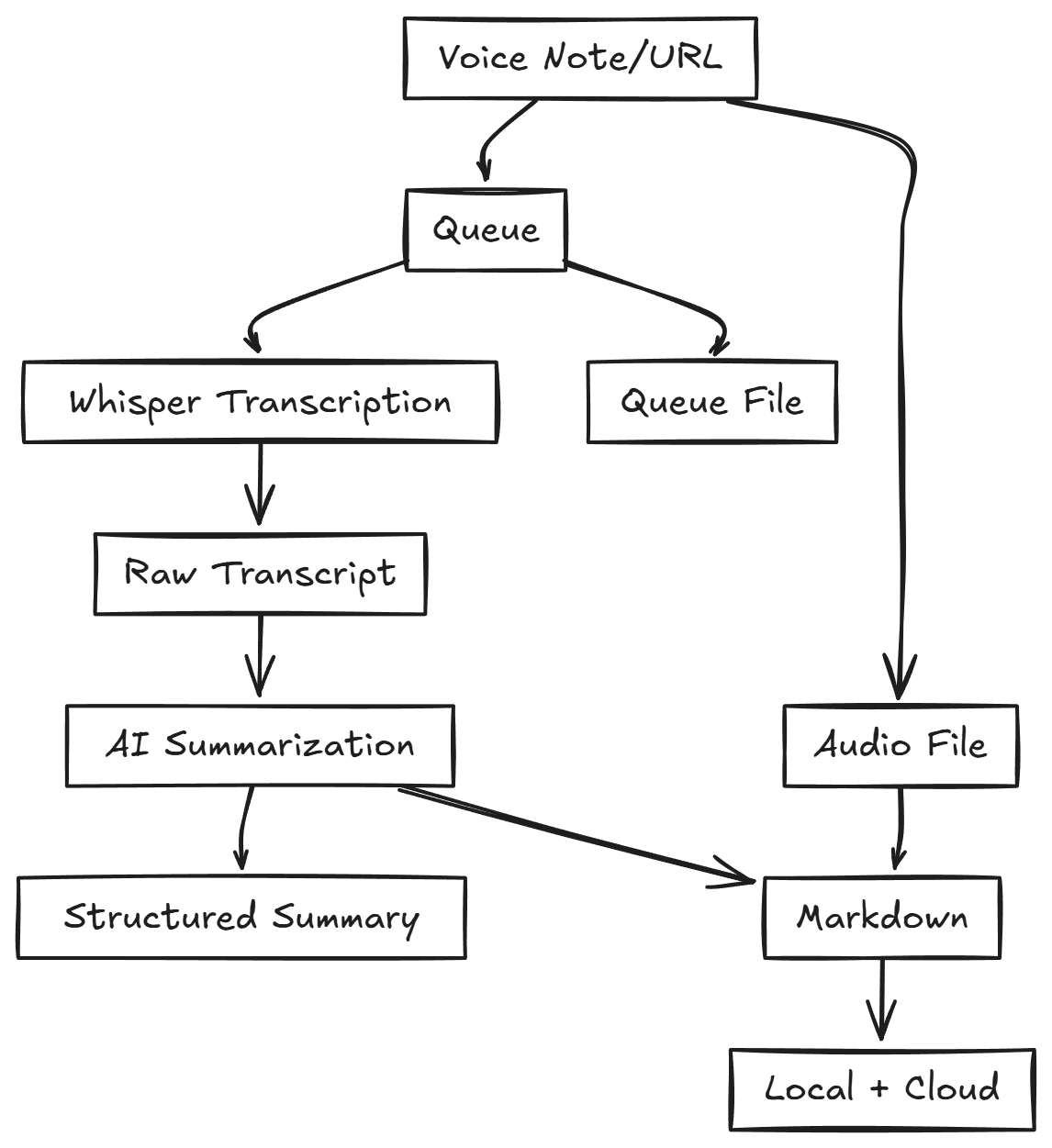
This isn't a single, monolithic application. It's a system of components, each with a specific job.
To dig more deeply into the code or to fork it and adapt to your own workflow, check it out on GitHub here: https://github.com/joreilly86/whisper_2.0
The system is composed of:
A User Interface: Simple batch scripts (
select_and_process.bat) that let me drag-and-drop a file for processing. No complex GUI needed.A Queue: A simple text file (
processing_queue.txt) acts as a persistent list of jobs. This is robust. If the script fails, the queue remains, and no work is lost.The Engine: The main orchestrator at
src/whisper_2_0/main.pycoordinates modules for each part of the process.The Transcription Service: Prioritizes Groq API (using
whisper-large-v3-turbo) and falls back to OpenAI'swhisper-1model if the primary service fails or you just want to stick with OpenAI. I think Groq is better, faster and cheaper.The Analyst: An LLM (I recommend Gemini Pro 2.5, but I’ve included a GPT-4o fallback) takes the raw transcript and synthesizes it into structured minutes based on a custom prompt I wrote - you can adapt this to your own needs.
The Archive: A dual-storage system that saves a local Markdown backup and pushes the final notes to a Notion database, which is where I track and manage most of my project work.
Key Code Snippets
Let's examine a few parts of the main script (process_voice_notes.py) that demonstrate some engineering choices.
Audio Chunking
The Whisper API has a file size limit of around 25 MB. A 90-minute design meeting recorded in high quality will far exceed this. The solution is to break the audio into smaller chunks. But how do you determine the right size? You could hard-code a 10-minute segment length, but that's inefficient. A more robust approach is to calculate the segment duration based on the target bitrate and the API's file size limit.
def estimate_segment_duration_ms(
audio_duration_ms, audio_channels, target_bitrate_kbps_str, max_size_bytes
):
"""Estimate optimal segment duration for audio chunking."""
try:
target_bitrate_kbps = int(target_bitrate_kbps_str.replace("k", ""))
except ValueError:
print(f"Error: Invalid target bitrate format: {target_bitrate_kbps_str}")
return None
# ... error checking ...
bytes_per_second_at_target_bitrate = (target_bitrate_kbps * 1000) / 8
# ... error checking ...
max_duration_seconds_for_chunk = max_size_bytes / bytes_per_second_at_target_bitrate
estimated_chunk_duration_ms = math.floor(max_duration_seconds_for_chunk * 1000)
return min(estimated_chunk_duration_ms, audio_duration_ms)This function calculates the maximum audio duration (in milliseconds) that will result in a file just under the MAX_CHUNK_SIZE_BYTES limit when encoded at the TARGET_BITRATE_KBPS. It ensures each chunk is as large as possible without exceeding the API limit, minimizing the number of API calls and potential transcription errors at chunk boundaries.
A robust system doesn't fail because one component is down. The transcription logic implements a clear fallback hierarchy:
def transcribe_audio_file(file_path):
"""Transcribe audio file using Groq Whisper first, then OpenAI as fallback."""
# Try Groq first (faster, cheaper)
transcript = transcribe_with_groq(file_path)
if transcript:
return transcript
print("Groq failed, trying OpenAI...")
# Fallback to OpenAI Whisper API
# [OpenAI processing logic]This design ensures that if your primary service is rate-limited or experiencing issues, processing continues with the backup service.
The Summarization Prompt
The transcription itself is just raw data. The transformation into useful knowledge happens during the summarization step. The quality of the output is a direct function of the quality of the instructions given to the LLM.
I have a dedicated prompt file (post_processing_prompt.txt) that turns a powerful, general-purpose LLM into a more refined specialist engineering minute taker. This has made a huge difference in the specificity and quality of the outputs.
Here's a snippet from that prompt (full prompt is here):
You are a senior engineering analyst skilled in summarizing technical and project coordination meetings...
Focus on technical accuracy. Use correct civil/structural/geotechnical/construction terminology...
Remove filler, greetings, or informal remarks unless they provide useful context.
Retain engineering constraints, design assumptions, and coordination needs.
Distinguish between decisions vs. open questions or pending items.This level of detailed instruction is how you get high-quality, structured output. This is the part of the system that is most valuable and easiest to customize. You can, and should, create your own prompt that reflects the specific needs of your projects and discipline.
Queue Management
Rather than processing files immediately, everything goes through a persistent queue system:
def load_queue():
"""Load processing queue from file."""
queue_items = []
if os.path.exists(QUEUE_FILE):
with open(QUEUE_FILE, "r") as f:
for line in f:
line = line.strip()
if line and not line.startswith('#'):
queue_items.append(line)
return queue_itemsThis prioritizes reliability over automation. You control when files are processed, which prevents issues with temporary files, ongoing recordings, or network hiccups during live meetings. The queue persists between sessions, so interrupted processing can resume exactly where it left off. This is a feature that evolved as I made annoying blunders.
Local vs. API: A Note on Security and Overhead
You might be wondering why I'm using paid APIs instead of a local instance of Whisper. It's a classic engineering trade-off involving speed, cost, and convenience.
Local Whisper: Running a local version gives you maximum data privacy and zero per-use cost. However, it comes with significant computational overhead. Transcribing a long meeting can tie up your machine's resources, especially GPU, making it difficult to do other intensive work. The setup and maintenance of the environment (CUDA drivers, Python dependencies, etc.) is also a non-trivial, ongoing task. This is how I started but it became so annoying, I pivoted and now use the API to free up my resources.
Paid APIs (Groq and OpenAI): This script actually uses a two-tiered approach. It first attempts to use the Groq API, which provides access to Whisper models at high speeds, often faster than real-time. This is my preferred method for its efficiency. If Groq is unavailable or fails, the script automatically falls back to the standard OpenAI Whisper API. This two-step process creates a more resilient system. These services offload the computational work, the processing is fast, and they don't impact your local machine's performance. For my workflow, this is a winning trade-off.
A critical note on security: Reputable, paid APIs from major providers like OpenAI, Google, and Groq generally have strong data retention and security policies suitable for most commercial work. However, you must exercise your own professional discretion. Some clients or projects may have specific, stringent requirements that forbid the use of third-party services for processing sensitive data. Always verify compliance before building a similar tool for a specific project.
⚠️ Disclosing that you are recording a meeting should be standard practice. Always consult your local laws to ensure you obtain the required consent from all participants.
Building Your Own Version
The barrier to entry is lower than you think. This tool was built by assembling a set of robust, open-source components defined in the pyproject.toml file, including:
AI Clients:
groq,openai, andgoogle-generativeaiare used to interact with the transcription and summarization services.Audio Processing:
pydubhandles all the audio manipulation and chunking.Database Integration:
notion-clientis used to communicate with the Notion API.
Getting Started
Step 1: Fork and Configure (15 minutes)
Clone the repository from GitHub
Copy
.env.exampleto.envand add your API keysInstall dependencies with
uv sync
Step 2: Test the System (5 minutes)
# Test basic functionality
uv run tests/test_voice_system.py
# Process your first meeting
uv run scripts/process_voice_notes.py --interactiveStep 3: Customize for Your Workflow (30 minutes)
Edit
post_processing_prompt.txtto match your meeting types and terminologyConfigure your preferred storage destination (Notion, SharePoint, etc.)
Adjust the batch scripts for your typical file locations
Real-World Implementation
After using this system for months on my projects, here's what I've observed:
Meeting Participation Improved: I can focus on technical discussions without missing critical details or action items.
Documentation Quality: Structured meeting minutes are immediately available for project files and client communications.
Cost Control: Processing 20+ hours of meetings monthly costs under $1 in API fees (whisper-large-v3-turbo is $0.04/hour as of July 28, 2025). Compare that to $20-30 per month for yet another commercial AI service.
Data Sovereignty: Sensitive design discussions stay within my control, meeting client confidentiality requirements.
Closing
The point is not to copy this tool verbatim, but to see it as a case study. Look at your own workflow. Find the bottlenecks, the repetitive, low-value tasks that consume your time and cognitive energy. What small, robust tool could you build to solve it?
This system represents a broader principle: build focused, reliable tools that solve specific problems efficiently. Rather than surrendering your workflow to external services, create purpose-built solutions that integrate with your existing processes. When you control the tools, you control the workflow.
A small investment in building your own system pays dividends in efficiency, control, and professional autonomy.
I use this tool daily. It’s a great way to stay engaged while ensuring you don’t miss important details.
What kinds of tools are you building to support your own workflow?
If you find this useful, please share, we are all on the same journey.
See you in the next one.
James 🌊