

#003 - Machine Learning for Civil and Structural Engineers | 01: The Fundamentals
A high-level overview for engineers on how machine learning works and how you can use it for various civil and structural engineering applications.

This article is a primer for engineers, intended to arm you with the information you need to dig deeper on the topic of machine learning.
Introduction
Machine learning (ML) is a hot topic these days, and it feels like a buzzword that gets thrown around. Still, it’s incredibly useful for engineers to gain practical insights into real data across a broad spectrum of use cases.
In this article, we delve into the fundamentals of machine learning, focusing on its relevance and applications. We'll explore the core concept of linear regression and its evolution into deep learning. This will take you about 10 mins or less to read but I think it’s a decent primer on the topic and will arm you with the information you need to dig deeper.
You can find the code examples discussed herein on my Github.
I’m confident that many engineers can quickly learn to use machine learning tools to gain faster and more accurate insights into their data than ever before. Each year, I see more and more data being produced for projects, often not used to its full potential. Learning how to leverage this data is a huge advantage.
Understanding Machine Learning
Machine learning is all about training models to learn from data.
“OK sure, but what do you mean by models?”
Great question, hypothetical reader. A model is simply a tool to make predictions based on data. The model's accuracy depends on the data's quality and depth.
Other factors also play a significant role. The choice of machine learning algorithm and the tuning of hyperparameters (i.e. settings for how the model learns from the data) can significantly impact the model's performance. Selecting an appropriate algorithm for the problem at hand and optimizing hyperparameters can lead to more accurate predictions, reinforcing the model's utility in practical applications.
There are many machine learning models and methods, but today, we’ll take a high-level overview of two big hitters: Linear Regression and Deep Learning.
Linear Regression
Linear regression is a foundational machine learning method and probably the best starting point for those new to the topic. It involves modelling data to make predictions based on linear relationships. Consider a civil or structural engineering project where we collected data for 1000 concrete samples, maybe during mix design, construction, or both.
Our data includes columns (also called features in the ML world) representing different properties of the sample, such as the amount of cement, water, fly ash, superplasticizer, age, strength, and more for each concrete sample.
Linear regression helps us assign weights (an importance factor) to each property. Maybe we think the water content is more important than the amount of superplasticizer, so we modify the weights accordingly. This enables accurate predictions of concrete strength. Then, we compare our predicted strength values with the recorded concrete strength values to validate our work and verify that our model reflects reality. This step is where we ‘train’ the model.
See below for a simplified version, the blue line represents the ‘best fit’, which generalizes the relationship between x (actual strength) and y (predicted strength). The red dots signify the model's predictions, which should ideally align closely with the actual recorded values to indicate a well-trained model.
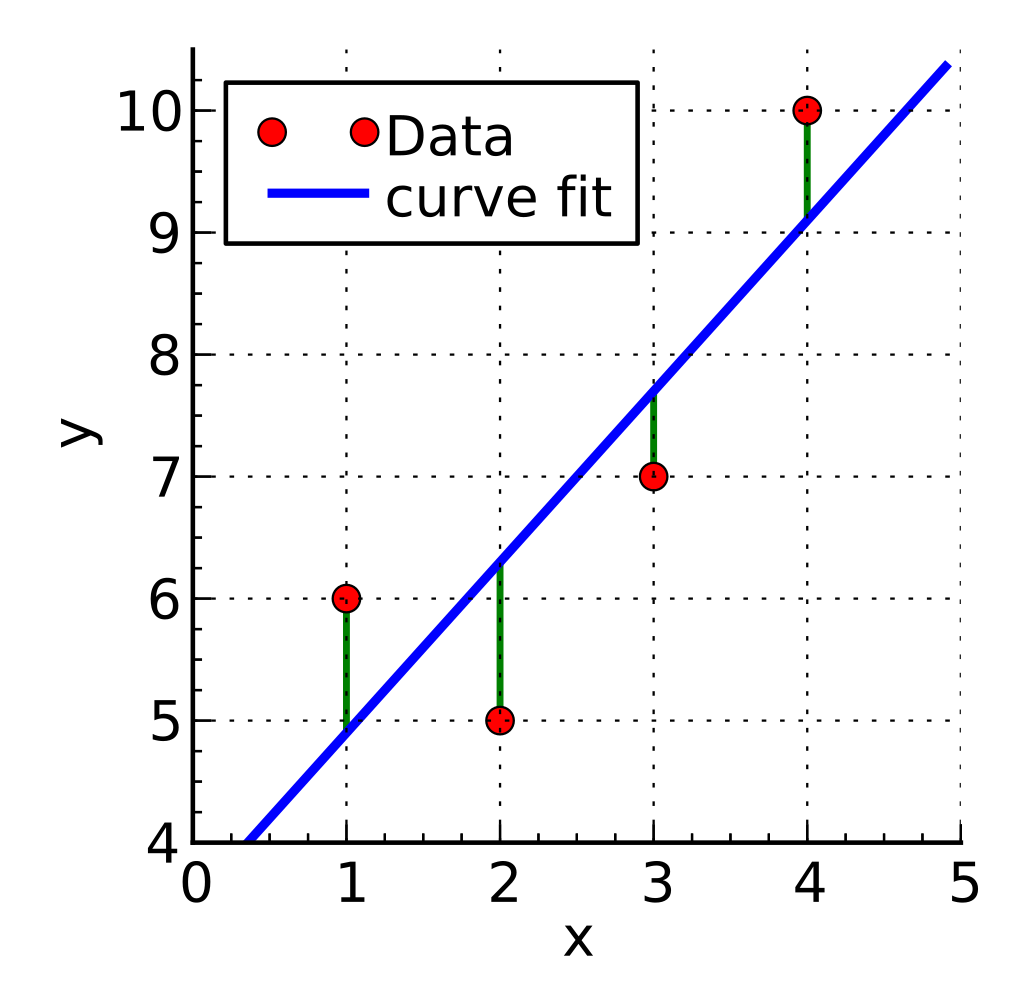
If formulas aren't your focus, you can still grasp the general working principles.
The mathematical equation for a simple linear regression model in machine learning is usually written as:
Here:
y: The target variable, in this case, 'Strength'.
β_0: The bias term, also known as the intercept.
β_1, β_2, ..., β_p: The coefficients or weights for each feature variable.
x_1, x_2, ..., x_p: The feature variables (e.g., Cement, Slag, Age, etc.).
ϵ: The error term, assumed to be normally distributed with a mean of zero.
Deep Learning

Moving beyond linear regression, deep learning introduces neural networks with multiple layers. Deep learning models, particularly feedforward neural networks like the one we’ve used, don't have a simple formula like linear regression. However, the basic operation can be expressed for a single layer as:
Here:
y: Output of the layer, which serves as the input for the next layer.
Activation: An activation function is applied to each element of the layer's output. It introduces non-linearity into the network, enabling the model to learn from the error and make adjustments during training.
W: Weight matrix for the layer.
x: Input vector to the layer.
b: Bias vector for the layer.
Bear with me here as we look at the structure of a deep learning model. It can be challenging to conceptualize, but pay close attention to the concepts described below.
Deep Learning Structure
A deep learning model comprises an input layer, a hidden layer (could be a few or many) and an output layer.
Input Layer: The first layer represents features from the dataset. One node per feature (e.g.' water content’ would be a feature in our example, or ‘age’).
Hidden Layers: Layers between input and output, where the learning happens. Each node in a hidden layer represents a learned attribute and is connected to all nodes in the adjacent layers. Many mysterious computations occur in these layers and are beyond this article’s scope.
Output Layer: The final layer represents the prediction or classification.
Some key deep learning concepts to be familiar with:
Nodes: Within each layer, nodes take weighted inputs from previous layer nodes, apply an activation function, and pass the output to the next layer.
Forward Propagation: Data moves from the input layer, through hidden layers, to the output layer. Each node sums its weighted inputs and applies an activation function to produce its output.
Backpropagation: The algorithm adjusts weights to minimize error between predicted and actual output, usually using gradient descent.
Activation Function: A mathematical function applied at each node, introducing non-linearity.
Weights and Biases: These are parameters learned during training. Weights control the influence of nodes, and biases allow for flexibility in the model.
While more complex, deep learning offers better approximations for intricate datasets. However, guarding against overfitting is critical.
Overfitting occurs when a machine learning model learns the training data too well, including its noise and outliers, leading to poor performance on new, unseen data. The model becomes too specialized to the training set and lacks generalization. This is often hard to see because you’re so focused on optimizing your predicted vs actual values. I have fallen into this trap.
Comparing the Models
Check out the plot below, where I’ve compared the two methods for predicting concrete strength.
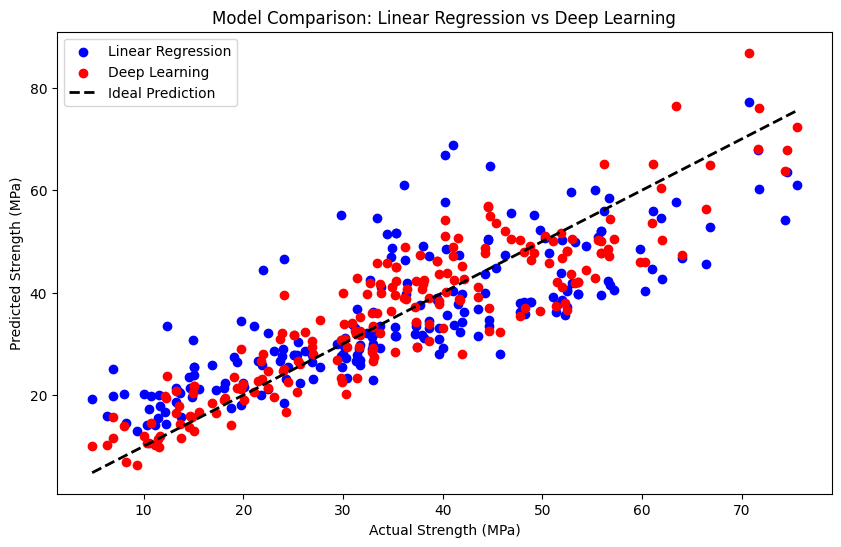
Key Insights
A tighter spread of data points in the deep learning model's plot (red) indicates that its predictions are closer to the actual strength values than the linear regression model (blue). This can be attributed to several factors:
Model Complexity: Deep learning models can capture complex non-linear relationships, which might be present in your data.
Feature Interactions: Deep learning models can learn to recognize interactions between features, which linear models might not capture effectively.
Parameter Tuning: Deep learning models have more hyperparameters, offering a more nuanced fit to the data during training. In my case, I just went with the basic, out-of-the-box Keras Sequential Model’. This applies to most of my use cases.
Data Scale: Deep learning can sometimes handle varying scales of input features better, although it's generally good practice to normalize or standardize features for both types of models.
Optimization: The optimization techniques used in deep learning can sometimes result in a more accurate model, especially when the loss function is well-suited to the problem. The loss function is a measure of how close your predicted values are to the actual values. During training, you want to minimize your loss function.
Keep in mind that a tighter spread doesn't always mean a "better" model. It could also indicate overfitting, where the model learns the training data too well but performs poorly on unseen data. Always validate the model's performance using separate test data and consider other evaluation metrics.
If you’re interested in this model, download the code from GitHub.
Application in Real Life:
What can you use machine learning for?
This is really just dependent upon the data you have, your objectives and your creativity. But I’ll list a few of the use cases for which I have implemented Machine Learning Models and also some ideas I have for the future.
Predicting Concrete Strength Based on Test Results:
Method: Regression algorithms like Random Forest or Support Vector Machines.
Data: Features include the amount of cement, water, age, and additives.
Achievement: Train the model to learn the relationships between these features and the concrete's ultimate strength. Use it to predict the strength of new samples.
Predicting Soil Bearing Capacity Based on Soil Samples and NPT Values:
Method: Decision Trees or k-Nearest Neighbors.
Data: Soil type, moisture content, NPT (Standard Penetration Test) values.
Achievement: Utilize these features to train a model to predict the bearing capacity for construction or foundation design.
Predicting Generation Revenue for Run-of-River Hydroelectric Facilities Based on In-Stream Flows:
Method: Time-series algorithms.
Data: Historical in-stream flow rates, and electricity prices.
Achievement: Forecast generation capacities and revenue based on variable in-stream flow rates.
Predicting Generation Revenue for Pumped-Storage Hydro Projects Based on Grid Demand/Supply:
Method: Neural Networks or Gradient Boosting.
Data: Grid demand/supply curves, electricity rates, operational costs.
Achievement: Model the complex relationships to predict the optimal times to pump or generate for maximum revenue.
Parametric Cost Estimates Based on Past Project Cost Data (a future use-case):
Method: Linear Regression or Bayesian methods.
Data: Past cost data, project duration, labour used, materials cost.
Achievement: Use past project data to develop a model that can provide cost estimates for future projects, aiding in budget planning.
Each application involves data collection, preprocessing, feature engineering, model selection, training, validation, and deployment into a real-world system or process.
No method is foolproof but the flexibility and the ease of applying these methods through Python is vastly superior to trying to solve the same problems in MS Excel.
Challenges
While machine learning offers powerful tools for various applications, mastering it has hurdles. Key challenges include understanding and managing your data, selecting the appropriate model, and vigilant monitoring to circumvent issues like overfitting (I am guilty on all counts here).
How Much Math Do You Need?
Contrary to popular belief, you don't have to be a statistician or a mathematician to leverage machine learning effectively. This major misconception kept me out of the loop for a long time. Anyone can use ML techniques.
While understanding the core principles of linear algebra, calculus, and statistics can deepen your understanding, many libraries and frameworks have abstracted the complexity away. However, a basic grasp of the following areas could be beneficial:
Statistics: To understand data distribution, variance, and bias.
Linear Algebra: To grasp how data is manipulated within algorithms.
Calculus: To understand optimization techniques like gradient descent.
In reality, you pick up these aspects quickly once you start building models. It’s much more intuitive to get rolling on a model than it is first to master Bayesian statistics.
Real-World Usage Without Deep Mathematical Insight
Many professionals in other non-engineering disciplines successfully implement machine learning models without delving into the underlying mathematics. Tools like scikit-learn or TensorFlow offer pre-built functions and methods that automate most of the intricate calculations.
Here's a practical approach:
Understand Your Data: Know what each feature (property) represents and how it correlates with what you're trying to predict.
Model Selection: Choose a model that suits your problem. Libraries often include a variety of algorithms for common tasks.
Monitoring: Use metrics like accuracy, precision, and recall to evaluate performance. Watch out for signs of overfitting, like discrepancies between training and validation accuracy.
By focusing on the practical aspects, you can utilize machine learning tools effectively without becoming engrossed in the mathematical details.
Conclusion
In conclusion, machine learning is a powerful tool that empowers us to decipher complex patterns and make data-driven predictions. Whether calculating quantities for roadway excavation or investigating the stress distribution of thermal loads on mass concrete, mastering machine learning fundamentals can revolutionize your problem-solving approach.
By understanding your data and selecting the suitable model, you can harness the potential of machine learning to tackle a wide array of real-world engineering challenges.
Please let me know if you’re interested in more posts on this topic!
Thanks for reading; see you next time on flocode.
James 🌊