

#014 - Machine Learning for Civil and Structural Engineers | 02: Linear Regression
A foundational statistical method widely used in data science and machine learning. This introduction clarifies its purpose in an engineering context.

Welcome back to our 'Machine Learning for Civil and Structural Engineering' series. In this installment, we delve into Linear Regression, the foundational method in Machine Learning.
This post delves into the essentials of linear regression, its mathematical underpinnings, and a practical Python-based example in an engineering context. We'll explore how linear regression can be applied to predict concrete strength based on factors like age, aggregate size, and water content.
Other posts in this series:
#003 - Machine Learning for Civil and Structural Engineers | 01: The Fundamentals

What is Linear Regression?
It’s a statistical method that allows us to understand and quantify the relationship between variables.
While statisticians remind us that Linear Regression is a well-established statistical technique rather than a novel innovation, its relevance has surged alongside the growing popularity of AI and machine learning tools.
In machine learning, linear regression is used for predictive modelling, where the algorithm learns from a set of data to make predictions about new, unseen data. Here’s how linear regression fits into the broader context of machine learning:
Supervised Learning: Linear regression is a supervised learning algorithm that learns from ‘labelled’ training data. The algorithm uses input-output pairs to learn a mapping from inputs to outputs.
Regression Analysis: This technique in machine learning is about predicting a specific number (like guessing your pet's exact weight), not just choosing a category or ‘classification’ (like deciding if your pet is heavy or light). It's part of regression analysis, where the goal is to find precise values, contrasting with classification, which is more about sorting into groups.
Simplicity and Interpretability: Despite being a basic technique, linear regression is widely used due to its simplicity and the interpretability of its results. It serves as a starting point for understanding more complex algorithms.
Foundation for Advanced Techniques: Linear regression principles are foundational for understanding more complex models in machine learning. Many advanced techniques, like neural networks, can be seen as extensions or sophistications of basic regression analysis.
Real-World Applications: In engineering and other fields, linear regression is used for forecasting, trend analysis, and determining the strength of relationships between variables. You can apply the pet analogy to all sorts of engineering problems.
Calculate a bridge's load rating for peak axle loads rather than broadly categorizing it as 'safe' or 'unsafe.’
Predict a building’s energy consumption based on variables like outside temperature, building size, and occupancy.
Estimate the exact number of vehicles that will travel on a road during peak hours, as opposed to simply labelling roads as 'congested' or 'clear.’
Tool for Data Analysis: In the context of Python programming for engineers, linear regression can be implemented using libraries such as Scikit-learn, TensorFlow and Pytorch, providing a powerful tool for data analysis and modelling.
So, while linear regression is a statistical method, its role in machine learning, particularly as a tool for prediction and analysis, is significant. It bridges traditional statistical analysis and modern machine-learning techniques, making it a valuable skill for engineers interested in integrating Python and machine learning into their professional arsenal.
This post explores the essentials of linear regression, its mathematical underpinnings, and a practical Python-based example in an engineering context. We'll explore how linear regression can be applied to predict concrete strength based on factors like age, aggregate size, and water content.
The Concept of Linear Regression
Linear regression is finding a linear relationship between a dependent variable and one or more independent variables. In engineering, this translates to understanding how various factors (independent variables) influence an outcome (dependent variable). For instance, how does the age of concrete affect its strength? Linear regression helps answer such questions by fitting a line that best represents the data.
Mathematical Foundations
The mathematical model of linear regression is y = mx + b
This equation might strike a chord of recognition deep in the dusty corners of your brain. This formula is the classic algebraic expression for a straight line. Here's a closer look:
y is the dependent variable (e.g., concrete strength). It's what we're trying to predict or understand.
x is the independent variable (e.g., the age of concrete, water content, aggregate content, or fly ash content). It's what we think might influence y.
m is the slope of the line. This tells us how much y (concrete strength) is expected to change when x (age of concrete) changes by one unit. In other words, it quantifies the effect of x on y.
b is the y-intercept. This is where the line intersects the y-axis, indicating the value of y when x is zero. In practical terms, for our example, it could represent the inherent strength of the concrete before considering the effects of age or other variables.
In linear regression, the use of this familiar equation is beneficial. It's not just a line on a graph; it also represents the relationship between variables in a dataset. Linear regression aims to find the values of m and b that best fit the data. This process, known as least squares regression, aims to minimize the discrepancies between the predicted values (points predicted along the straight line) and the actual data points. You are, basically, trying to minimize the errors in your guesswork.
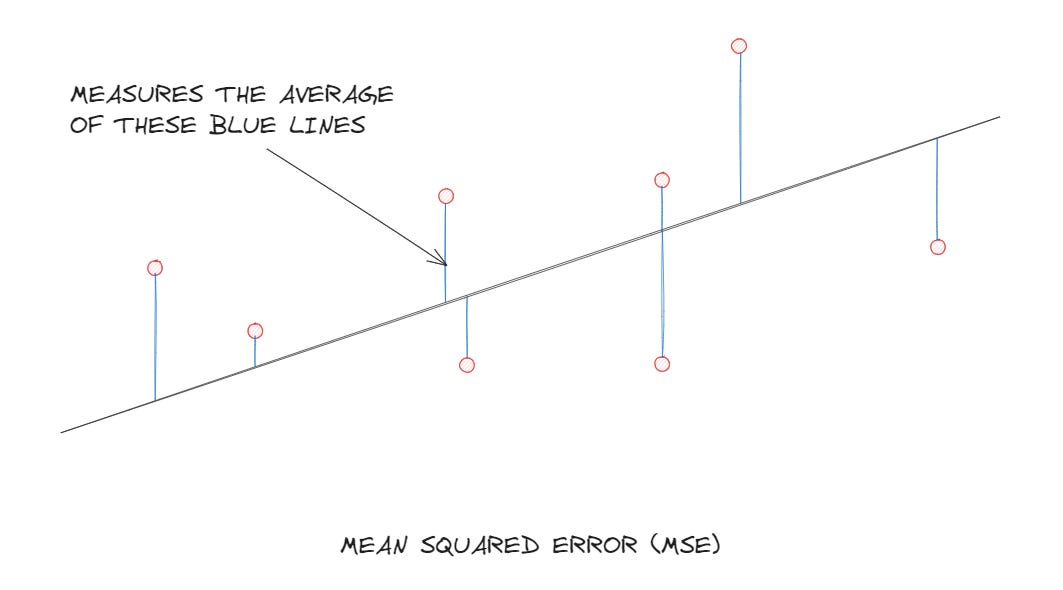
The beauty of this formula lies in its simplicity. It bridges the basic concepts of algebra to the complex realms of data analysis and machine learning. This connection can be enlightening, linking mathematical concepts learned in the classroom many years ago to advanced analytical techniques used in professional engineering contexts. I swore I would never need to use that stuff again, but here we are.
A Simple Python Example in Engineering
Let’s consider an engineering scenario where we want to predict the strength of concrete based on its age, aggregate size, and water content. We can use Python's libraries like Pandas for data handling and Scikit-learn for implementing linear regression.
I touched on this in a previous post - Machine Learning for Civil and Structural Engineers | 01: The Fundamentals.
But today, we’ll delve a little deeper into the nuts and bolts of it. You can find everything you need for this example on my GitHub.
Steps:
Data Preparation: Collect data on concrete strength, age, aggregate size, and water content.
Data Analysis: Use Pandas to explore and preprocess the data.
Model Building: Implement linear regression using Scikit-learn, defining the independent variables (age, aggregate size, water content) and the dependent variable (concrete strength).
Model Training: Train the model on the dataset to find the best-fit line.
Prediction: Use the model to predict concrete strength based on new input values.
Code
If this is over your head, don’t worry. You can review the descriptions of the functions after the code blocks below. That will help explain what’s happening at key steps. You’ll need a basic understanding of Python to read this code block.
Siderant: Substack’s code blocks are disgusting 🤮. If you find it difficult to read and parse code on Substack, you’re not crazy.
No syntax highlighting or formatting options are available yet. This is a common complaint on Substack, so hopefully, they will address this soon, and we can all stop stabbing ourselves in the eyes.
For simple perusal, I’ve also saved this example as a Google Colab Jupyter Notebook; feel free to open it up and mess around.
#install the required dependencies
pip install pandas
pip install scikit-learn
pip install matplotlibimport pandas as pd
#Bring in your data
df_concrete = pd.read_csv('concrete_data.csv') # replace with your csv file path; this assumes it's in the root folder.
# Display the first few rows to understand its structure
df_concrete.head()
#Set up your Linear Regression Model
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Features and Target
X = df_concrete.drop('Strength', axis=1)
y = df_concrete['Strength']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Initialize and train the model
model = LinearRegression()
model.fit(X_train, y_train)
# Make predictions and evaluate the model
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
# Mean Squared Error
print('Mean Squared Error:', mse)
# Plot your model
import matplotlib.pyplot as plt
# Linear Regression Predictions
y_pred_lr = model.predict(X_test)
# Linear Regression Predictions
# Assuming 'y_pred_lr' contains predictions from the linear regression model
plt.figure(figsize=(10, 6))
plt.scatter(y_test, y_pred_lr, color='blue')
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'k--', lw=2)
plt.xlabel('Actual Strength (MPa)')
plt.ylabel('Predicted Strength (MPa)')
plt.title('Linear Regression Model')
plt.show()Flocode’s machine learning repository on GitHub is still in development, but if you want to look, it’s here. I’ll be adding more methods and ideas as we progress.
Scikit-Learn
Let's look at some of the key functions and methods from the Scikit-learn (sklearn) library used in this linear regression example. Understanding what these methods do means you can pull them out of the bag at the right time.
train_test_split (from sklearn.model_selection):
Purpose: This function splits a dataset into training and testing subsets.
Usage:
train_test_split(X, y, test_size=0.2, random_state=42)splits the featuresXand targetyinto training and testing sets.test_size=0.2means 20% of the data is reserved for testing.random_stateis set for reproducibility, ensuring the split is the same each time the code is run.This is a typical approach to organizing your data between test and training data.
Training Set: This is the subset of data used to train the model. The model learns the relationships within this data, trying to understand how the input features (X) relate to the target variable (y).
Testing Set: After the model has been trained, evaluating its performance on data it hasn't seen before is important. This is where the testing set comes in. It helps assess how well the model generalizes to new, unseen data.
test_size=0.2: By setting this parameter to 0.2, you're allocating 20% of the entire dataset for testing. This means if you have 100 data points, 20 will be used for testing and the remaining 80 for training. The choice of this split can vary depending on the size and specifics of the dataset, but an 80-20 or 70-30 split is quite common in practice.
random_state=42: Setting a
random_stateis akin to setting a seed for a random number generator. It ensures that the process of randomly splitting the dataset is repeatable and consistent across different runs. This is important for reproducibility of results. The number 42 is arbitrary - any number can be used as the seed.
Splitting data into training and testing sets is foundational in machine learning, helping to prevent issues like overfitting and underfitting and ensuring that the model's performance metrics are reliable.
LinearRegression (from sklearn.linear_model):
Purpose: This class is used to create a linear regression model. It aims to model the relationship between a dependent variable and one or more independent variables by fitting a linear equation to the observed data. The key objective of this linear model is to find the coefficients (represented by the slope and intercept in a simple linear regression) that minimize the residual sum of squares. The residual sum of squares is the sum of the squared differences between the observed values and the values predicted by the model. By minimizing this value, the model strives to achieve the best possible fit to the data, capturing the underlying trend accurately.
Usage:
model = LinearRegression()initializes the model.model.fit(X_train, y_train)trains the model on the training dataset.
mean_squared_error (from sklearn.metrics):
Purpose: It's a function to calculate the Mean Squared Error (MSE), a common metric to evaluate the performance of a regression model.
Usage:
mse = mean_squared_error(y_test, y_pred)computes the MSE between the actual valuesy_testand the predicted valuesy_pred. A lower MSE indicates a better-fitting model.
model.predict():
Purpose: This method makes predictions using the trained linear regression model.
Usage:
y_pred = model.predict(X_test)uses the trained model to predict outcomes based on the feature setX_test.
These functions and methods are integral to machine learning in Python using Scikit-learn. Understanding them is crucial for anyone applying machine learning techniques in engineering or other fields. The train_test_split function ensures that the model is tested on unseen data, providing a realistic evaluation of its performance. LinearRegression is a straightforward way to implement linear regression, one of the most fundamental machine learning algorithms. The mean_squared_error function provides a quantitative measure of the model's accuracy, and model.predict() is essential for applying the model to make predictions, the ultimate goal of most machine learning tasks.
Conclusion
Linear regression, combined with Python's powerful libraries, provides engineers with a tool to make informed predictions and decisions. Engineers can optimize processes, enhance material quality, and improve their project outcomes by understanding the relationship between various factors and outcomes.
The concrete strength model in today’s example is just one of many applications where linear regression can benefit engineering. As you can imagine, this same approach can be applied to any number of engineering scenarios where you have linear x y relationships.
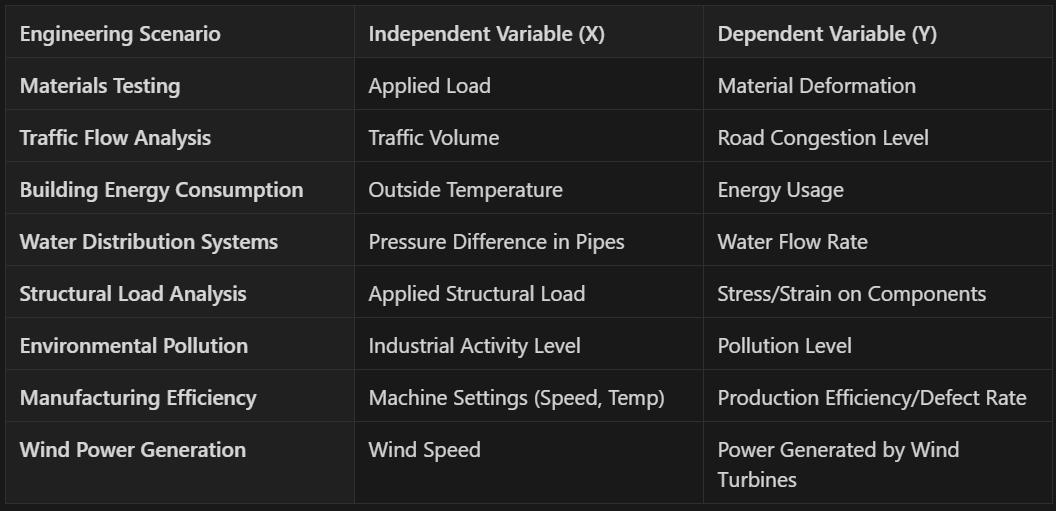
Takeaway
As you continue to explore Python's capabilities in your engineering journey, remember that the power of data analysis lies in its ability to transform numbers into actionable insights. Still, everything depends on the quality and relevance of your data.
Our next post in the machine learning series will cover ‘Logistic Regression’ for classification problems, which helps predict equipment failure, structural integrity, or flood risk predictions.
Thanks for reading! Please share this with your curious engineering friends, and I’ll see you in the next post.
James 🌊
Quite a detailed and simplified description!